
From Pandas to the Cloud: How I Accidentally Became a Container Evangelist

A few months ago, I was minding my own business—tuning data pipelines, optimizing our queries, and doing the usual data engineering work—when a curious message popped up on Teams.
“Hey, got a sec? We’ve got this demand forecasting script that’s... uh, getting out of hand. Can you take a look?”
Sure, why not?
The Forecasting Fiasco
The business team had been running their demand forecasting using a familiar tool—Pandas. It wasn’t flashy, but it worked. Well, sort of. The process pulled source data from multiple systems: CRM, Budgeting, Revenue and even a few Excel files manually emailed every week.
The pipeline (if you could call it that) involved:
- Opening the python project on someone’s personal laptop
- Running the main script
- Exporting results to CSVs
- Manually uploading those files to an Azure Storage container
- Then, pray that the files are uploaded successfully to the database, which occasionally failed due to formatting issues.
It was equal parts art, science, and daily anxiety.
Whose Turn Is It to Run the Forecast
The script wasn’t running on any server. It was tied—rather tragically—to whoever available to run it. Every week, a different analyst would try to run it.
I still remember the call I got one morning:
“Hey, I tried running the forecast and it’s throwing a weird error aboutopenpyxlandpyodbc. I don’t know what that means.”
I did. It meant someone’s Conda environment had gone rogue.
The business wasn’t just running forecasts. They were wrestling Conda environment, fighting PATH variables, and battling dependencies hell. It was a miracle anything worked at all.
Enter the Data Engineer
That’s when they came to me.
The request was simple enough: “Can we automate this?”
So I started looking at options:
- Azure Synapse Notebook? Tempting, but the script was packed with custom Python libraries, written using Python 3.7 that will not be compatible with the supported Synapse Spark 3.5 runtime.
- Azure Data Factory? Also an option, but converting a sprawling Pandas script into ADF data flows felt like translating poetry into assembly language.
After a few trials, I realized something important: we didn’t need to rewrite the logic—we just needed to containerize it.
A Job for Azure Container Jobs
And that’s when I discovered Azure Container Jobs.
No need for orchestration engines, no Kubernetes cluster to maintain, and no VM just sitting idle. I could:
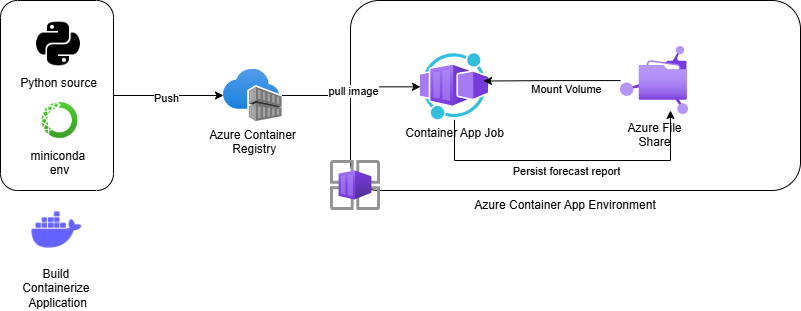
- Containerize the Python application into a Docker container
- Push it to Azure Container Registry
- Set up a Azure Container Apps Environment
- Create an Azure File Share and mount the volume in the container
- Create a Container App Job and schedule it to run once a week (or whenever needed), persisting the forecasting report in Azure File Share
Best of all? It ran the exact same environment every time. No more “it works on my laptop” debates. Here's what the solution looks like.
Dockerfile (Simplified)
To keep the size of the image down, I used a multi-stage build. This dramatically reduce the image size by 50%:
# Use the official Miniconda base image
FROM mcr.microsoft.com/devcontainers/miniconda:latest AS build
# Copy environment files
COPY environment.yml environment.yml
# Install system dependencies
RUN apt-get update && apt-get install -y --no-install-recommends \
&& apt-get clean \
&& rm -rf /var/lib/apt/lists/*
# Create a default conda environment
RUN conda env create -f environment.yml
# Install conda-pack:
RUN conda install -c conda-forge conda-pack
# Use conda-pack to create a virtual env
RUN conda-pack -n default -o /local/env.tar && \
mkdir /venv && cd /venv && tar xf /local/env.tar && \
rm /local/env.tar
# This makes the entire /venv directory truly self-contained and portable
RUN /venv/bin/conda-unpack
# We starts brand new, from a minimal base image without conda
# as the venv we built previously is completely self-sufficient
FROM debian:buster AS runtime
# Copy /venv from the previous stage:
COPY --from=build /venv /venv
# Add Conda Python to PATH
ENV PATH="/venv/bin:$PATH"
# Copy the main script
COPY forecasting_pipeline.py .
# Default run command
CMD ["python", "forecasting_pipeline.py"]
Example environment.yml
The trickiest part of this exercise was upgrading Python from 3.7 to 3.11, but it turned out to be a blessing in disguise — the newer version brought noticeable performance improvements, better error messages, and long-term support, making our container builds leaner and our data pipeline faster and more maintainable.
name: default
channels:
- conda-forge
- defaults
dependencies:
- python=3.11
- pandas
- numpy
- scipy
- plotly
- pyodbc
- azure-identity
- python-dateutil
- pip
- pip:
- python-dotenv
- sqlalchemy
Container Registry and Deployment
To deploy:
# Build the container
docker build -t forecasting-pipeline .
# Tag and push to ACR
az acr login --name myregistry
docker tag forecasting-pipeline myregistry.azurecr.io/forecasting-pipeline:latest
docker push myregistry.azurecr.io/forecasting-pipeline:latest
Then, schedule using an Azure Container Job with the Azure File Share mounted and appropriate secrets/environment variables passed in.
From Chaos to Confidence
Now the forecasting pipeline runs like clockwork. The business team doesn’t worry about conda environments or weird Excel edge cases. They just get their forecast files where they need them, when they need them.
I didn’t set out to become a DevOps-for-Pandas advocate. But sometimes the best solutions aren’t the flashiest—they’re the ones that quietly work, week after week.
And all it took was one container.
Epilogue: Lessons Learned
- Manual data pipelines are a hidden tax on productivity.
- Not everything needs to be rewritten—encapsulation can be powerful.
- Azure Container Jobs are a sweet spot between DIY infrastructure and fully managed orchestration.
If you’re a data engineer caught between business logic and bad environments, don’t overlook containers. Sometimes, all you need is a good Dockerfile and a quiet Sunday to set things right.